No.1808 - 1857 / 50 件表示
- 1857. 不偏分散の区間推定 投稿者:キッシー 投稿日:2022/09/19 (Mon) 16:57:23
- いつもお世話になっております
不偏分散の区間推定についての質問です
σL^2={(n-1)V}/χ^2(n-1、α/2)
σU^2={(n-1)V}/χ^2(n-1、1-α/2)
n=10、V=100、α=0.05の場合
σL^2≈47
σU^2≈333
ですが、α=1にすると
σL^2=σH^2≈107.88となりますが
どういう意味になるのでしょうか?
点推定V=100と一致すると思っていました
とんでもない意味不明な質問かもしれませんが
宜しくお願いします
- 1856. Re[1855]:[1854]:分散分析 投稿者:キッシー 投稿日:2022/05/20 (Fri) 15:44:37
- 今回も詳しいご回答をいただき
大変ありがとうございました
統計学は奥が深いですね
勉強ネタは尽きません
今後も宜しくお願いします
- 1855. Re[1854]:分散分析 投稿者:杉本典夫 [URL] 投稿日:2022/05/20 (Fri) 09:06:47
- >キッシーさん
お久しぶりです!(^o^)/
> ➀σA^2の計算をs,rの事例で教えていただきたいです
> ➁σA^2、σR^2を計算してその結果をどのように利用するものなのでしょうか
製薬業界で飯を食っていた時、製剤技術研究所からこのことを相談されたのでこの解説を書きました。
その事例は、医薬品のロット内分散とロット間分散を観測して、それが厚労省の基準を満足しているかどうかを検討する問題でした。
細かい数字は覚えていないので数字は仮のものですが、厚労省の基準では特定の5ロットについて、1ロットあたり10製剤を無作為抽出して力価を測定し、力価のロット内分散とロット間分散を求め、それが基準内であることを検証する必要がありました。
ところが諸般の事情で、1ロットあたり8製剤しか無作為抽出できなかったのです。
そこで本来のロット内繰り返し観測数をs=10とし、実際のロット内繰り返し観測数をr=8として、紹介した式を用いてロット内繰り返し観測数sが10の時のロット間分散σA2乗を推測したのです。
この時、r=8で実施したデータに一元配置分散分析を適用して、要因A(ロット間バラツキ)の分散がVA=10、残差(ロット内バラツキ)分散がVR=5だったとすると、ロット内繰り返し観測数をs=10にした時のロット間分散推測値σA2乗は次のようになります。
σA2乗 = VA/r + VR(1/s - 1/r) = 10/8 + 5×(1/10 - 1/8) = 1.125
r=8の時のロット間分散推測値σA2乗は次のようになります。
σA2乗 = (VA - VR)/r = (10 - 5) / 8 = 0.625
ロット内分散は次のようになります。
σR2乗 = 5
この計算から、本来は10例で実施すべきところを8例で実施すると、ロット間分散を過小評価してしまう可能性があることがわかります。
つまり品質管理用の場合は、決められとおりに実施するのが無難だということです。(^_-)
僕の経験では、この式を使ったのはその時だけであり、臨床試験や臨床研究などでは使ったことはありませんね。
- 1854. 分散分析 投稿者:キッシー 投稿日:2022/05/18 (Wed) 14:14:37
- 第4章
4.1多標本の計量値
(1)データに対応がない場合
2)多重比較
(注1)の最後の方に
「各水準の例数をsにした時のσA2推定値:σA^2=VA/r+VR(1/s-1/r)
品質管理などでは多くの場合、各水準の例数があらかじめ決められています。
ところが色々な事情でそれとは異なる例数で試験を行ってしまうことがあります
そのような時には、この式を利用して決められた例数で試験をした時の結果を推定することがきます。」
とありますが
➀σA^2の計算をs,rの事例で教えていただきたいです
私はs,rの定義が理解できていないと思っています
➁σA^2、σR^2を計算してその結果をどのように利用するものなのでしょうか
- 1853. Re[1852]:[1851]:クラメールの連関係数 投稿者:キッシー 投稿日:2021/11/30 (Tue) 12:15:12
- 直ぐに返信していただけるとは
大変、感謝しております
私の質問は、他のところまで読んで理解しておらず
愚問であり、すみませんでした
PS:
統計学入門のHPは凄いですね
考え方、式、数値での事例計算
分かり易いです。
引き続き活用させていただきます
- 1852. Re[1851]:クラメールの連関係数 投稿者:杉本典夫 [URL] 投稿日:2021/11/30 (Tue) 08:47:40
- >キッシーさん
初めまして、当館の館長を務めている”とものり”こと杉本と申します。
「統計学入門」を読んでいただき、ありがとうございます。m(_ _)m
> 連関係数の95%信頼区間の計算方法が知りたいので教えていただければ
> 助かります
連関係数の信頼区間の計算方法は、第4章第2節 多標本の計数値 (2)名義尺度(分類データ)の注(1)で説明してあります。
数式ばかりで少々わかりにくいと思いますが、じっくりと読んでみてください。(^_-)
http://www.snap-tck.com/room04/c01/stat/stat04/stat0402_2.html#note01
- 1851. クラメールの連関係数 投稿者:キッシー 投稿日:2021/11/29 (Mon) 15:13:09
- 5章の3ページ目
「○クラメールの連関係数:V=0.690 寄与率:R2=V2=0.476=φ2
検定=χ2検定:χo2=5.238(p=0.0221)>χ2(1,0.05)=3.841 … 有意水準5%で有意
連関係数の95%信頼区間 下限:VL=0.117 上限:VU=1」
とありますが
連関係数の95%信頼区間の計算方法が知りたいので教えていただければ
助かります
宜しくお願いします
ps:
その他のページは部分的にしか理解できておりませんが
非常に参考にさせていただいております
ありがとうございます
- 1850. 放送大学BSキャンパスex特集「感染症と人類~パンデミックを考える~」 投稿者:杉本典夫 [URL] 投稿日:2021/10/21 (Thu) 11:29:14
- 先日、紹介した放送大学のBSキャンパスex特集「日本人は疫病とどう闘ってきたのか」に続く、感染症シリーズです。
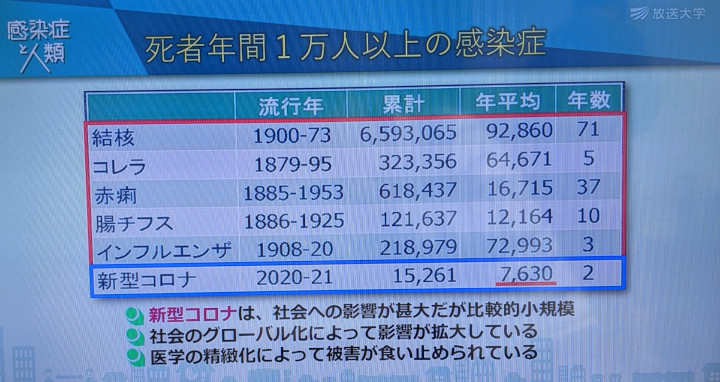
この特集の第1回「感染症の医学史」で、人類が経験した大規模感染症と日本における死者年間1万人以上の感染症を解説していました。この資料を見ると、過去の大規模感染症と比較すると今回のCOVID-19は感染者も死亡者も桁違いに少ないことがわかります。
この資料は人数で記載されていますが、発生当時の人口で割って感染率と死亡率にすると差がさらに大きくなります。例えば1918〜1920年に大流行した有名なスペイン風邪(A型インフルエンザ・パンデミック)は、世界で3年間で約5億人が感染し、約5,000万人が死亡しました。当時の世界人口は約20億人ですから、1年あたりの感染率は約8.3%、死亡率は0.83%です。日本では3年間で約2,300万人が感染し、約38万人が死亡しました。当時の日本の人口は約5,700万人ですから、1年あたりの感染率は約13%、死亡率は0.28%です。
それに対してCOVID-19は世界で2年間で1億9662万人が感染し、419万9千人が死亡しました。現在の世界人口は約77億人ですから、1年あたりの感染率は1.3%、死亡率は0.03%です。日本では2年間で91万人が感染し、1万5千人が死亡しました。現在の日本の人口は約1億2000万人ですから、1年あたりの感染率は0.4%、死亡率は0.006%です。この感染率と死亡率をスペイン風邪と比較すると、世界では10分の1〜30分の1程度、日本では30分の1〜50分の1程度です。
インフルエンザとCOVID-19は疾患の性質が似ているので、もしこれが100年前に流行したらスペイン風邪以上の死亡者を出したと思います。それが現在のところはスペイン風邪の10分の1〜50分の1程度の感染率と死亡率に抑えられているのは、先人達の命がけの努力による医学の発達と、それに裏打ちされた医療従事者の人達の命がけの努力の成果です。
天然痘は1980年にWHOが根絶宣言を出し、チフスもペストもコレラもインフルエンザもワクチンと治療法が開発されて、現在ではパンデミックを起こすような怖い感染症ではなくなりました。その結果、これらの感染症の恐ろしさが忘れられすぎたせいか、COVID-19の感染率と死亡率を現在の程度に抑えている奇跡的とも言える現在の状況と、近代医学の進歩の凄さが、残念ながら世間ではあまり認識されていないような気がします。(~_~;)
※こちらが、放送大学BSキャンパスex特集「感染症と人類~パンデミックを考える~」の公式サイトです。
https://www.ouj.ac.jp/hp/o_itiran/2021/1011.html
- 1849. 放送大学BSキャンパスex特集「日本人は疫病とどう闘ってきたのか」 投稿者:杉本典夫 [URL] 投稿日:2021/10/16 (Sat) 15:24:58
- 高温多湿で、しかも島国の日本は、古代から多くの疫病(感染症)が大流行し、社会や歴史の動きに大きな影響を与えてきました。
古代から、日本ではだいたい100年に1度くらいの頻度で、人口の20〜30%が死亡する疫病の大流行が起きました。日本は島国なので閉鎖集団(人の出入りが無く、かつ質が均一な集団)に近く、一旦、疫病が大流行すると集団免疫ができるまで流行が続きます。そして免疫を持つ人達が生存している間は再流行は起こらず、それらの人達がほぼ全員死亡し、免疫を持たない人ばかりになってから外国から病原菌やウイルスが持ち込まれると、また大流行が起こります。この間隔がだいたい100年くらいなのです。
この大流行とは別に、10〜20年に1度くらいの頻度で人口の5〜10%程度が死亡する疫病が流行しました。現在のCOVID-19は1年間で人口の0.01%(1万人/1億2千万人/1年間)が死亡しています。この程度の死亡率の疫病は、これまでの日本では、ほぼ毎年、流行していました。
そういった過去の疫病の歴史を調べると、時代や社会は違っても、人間の心理や行動面そして為政者が行う疫病対策――昔も今も日本の為政者は無為無策であり、疫病との闘いは全て医療従事者の個人的努力に任せていた!――には共通することが多々あります。
この「日本人は疫病とどう闘ってきたのか」は、前編「古代:天平のパンデミックの正体」と、後編「中近世:江戸の医療と疫病」の2回シリーズであり、現在のCOVID-19との闘いを考える上で大いに参考になると思います。再放送も何度かあると思いますので、興味のある方は、是非、観てやってください。(^_-)
https://www.ouj.ac.jp/hp/o_itiran/2021/0910.html
なお後編「中近世:江戸の医療と疫病」については、手塚治虫の傑作漫画「陽だまりの樹」が参考になるので、お薦めです。v(^_-)
https://ja.wikipedia.org/wiki/%E9%99%BD%E3%81%A0%E3%81%BE%E3%82%8A%E3%81%AE%E6%A8%B9
- 1848. 甲を着た古墳人と首飾りの古墳人 投稿者:杉本典夫 [URL] 投稿日:2021/10/16 (Sat) 15:23:19
- 先日、某旅雑誌に、僕のお気に入りの”日本のポンペイ”こと金井東裏遺跡のことが紹介されていました。この遺跡は古墳時代後期の6世紀頃のもので、近くにある榛名山の大噴火によって古墳時代の集落がそっくりそのまま火山灰に埋もれてしまった珍しい噴火遺跡です。
この遺跡の中央付近のほほ同じ場所から、甲(よろい)を着た古墳人(渡来系の40代男性)の骨と、首飾りをした古墳人(縄文系の30代女性)の骨、そして5歳前後の幼児(性別不明)の骨と、生後数ヶ月の乳児(性別不明)の骨が発見されました。
甲を着た男性は、骨の筋肉の付き具合から左利きで弓の鍛錬をしていて、乗馬をしていたと考えられています。首飾りの女性は上肢も下肢も発達していて、決してお姫様のような生活ではなく、しっかり働いていたと考えられています。そして骨に含まれる同位体元素の含量から、地元の群馬育ちではなく、長野の伊那谷あたりで育ち、そこから群馬に移住してきたのではないかと考えられています。また二人の乳幼児は群馬育ちらしく、甲を着た男性と首飾りの女性が群馬に移住した後、そこで生まれ育ったと考えられています。
ポンペイと違ってこれら4人の他には人骨はひとつも発見されず、代わりに多くの古墳人の足跡と馬の蹄(ひづめ)跡が発見されました。これらの足跡と蹄跡は榛名山を背にして東の方向に向かって整然と並んでいて、集落の人達が集団で避難したのではないかと考えられています。
このミステリアスな状況について、色々な説が提唱されています。縄文人のDNAを持つ僕は、次のようなドラマチックなストーリーを妄想しています。
弥生時代から古墳時代にかけて、長野の伊那谷にあった縄文人の集落に朝鮮半島から渡来した人達がやってきて、両者が協力して弥生の集落を営んでいました。そのうちに人口が増えて集落が手狭になったので、渡来系の長の息子と縄文系の巫女の娘が結婚し、集落の一部の人達を引き連れ、新天地を求めて東日本の群馬に集団移住することにしました。
彼等は、縄文人の慣習に従って神と仰ぐ火山(榛名山)の麓に近い土地を開拓し、新しい集落を造り上げました。ところがそのうちに榛名山の活動が激しくなり、近いうちに噴火すると予想されたので(火山を神と仰ぐ縄文人は火山の噴火を予想できたはずです)、集落の長はとりあえず集落の人達を安全な土地に集団避難させます。
巫女である彼の妻は、神(榛名山)の怒りを鎮めるために集落に残り、巫女の正装(首飾り等)をして神に祈りを捧げます。長は古墳時代の王の正装である甲を着て、妻を守り、一緒に神に祈りを捧げるために、妻と一緒に集落に残ります。
古墳時代の女性の結婚適齢期は15〜18歳くらいなので、もしかしたら二人には少年〜青年期の長男がいて、集落の人達を率いて避難させる一方、巫女を継がせるつもりの5歳の長女と乳飲み子を連れて集落に残ったのかもしれません。そして4人で神に祈りを捧げている最中に、不運にも榛名山が大噴火し、逃げる間もなく火砕流に埋もれてしまいました。
自らの身を犠牲にして神の怒りを鎮めるのが巫女の役目なので、神の怒りを鎮めるのに失敗した時は逃げずに運命を甘受すると彼女は覚悟していたのではないかと思います。そして集落の人達を避難させた上で、彼女と運命を共にした長のリーダーらしい立派な行動は、今の日本の政治家に爪の垢でも煎じて飲ませたい気がします。
ユーモラスな土偶に象徴されるように、縄文時代は戦争のない平等で平和な時代でした。ところが弥生時代になると階級が生じ、戦争が始まります。そして古墳時代になると戦争が終わってまた平和な時代になり、大規模な古墳と、土偶に似たユーモラスな埴輪が造られるようになります。古墳時代は、ちょうど江戸時代のように、戦乱と戦乱の間の、平和で安定した時代だったのかもしれません。
僕の勝手な願望ですが、首飾りの女性の複顔はもっと神秘的な美人にして、”群馬のヒミコ様”という愛称を付けて欲しいものです。(^_-)
http://www.gunmaibun.org/kanaiura/kofunzin/kofunzin_2510.pdf
http://kofunnomori.web.fc2.com/gunma/shibukawa/kanai_higashi_p2.jpg
- 1847. 「分水嶺 ドキュメント コロナ対策専門家会議」 投稿者:杉本典夫 [URL] 投稿日:2021/07/12 (Mon) 17:40:27
- ・「分水嶺 ドキュメント コロナ対策専門家会議」河合香織、岩波書店、2021年
2020年2月に発足し、7月に自ら解散を申し出て廃止されるまでの約5ヶ月間、未知の新型ウイルスに対して様々な指針を示した「コロナ対策専門家会議」。その波乱万丈の活動を専門家、政治家、官僚等、多くの関係者の証言で描く、迫真のノンフィクションです!(^o^)/
筆者は、自らの存在や考えを文中に出すことなく、冷静かつ客観的な筆致で、関係者の証言を淡々と記述しています。しかし、それにもかかわらず――あるいは、だからこそ――、感染を押さえ込み、患者を助けるために、自らの命を削ってまで懸命に奮闘する専門家の使命感と、都合の良い時だけ専門家の言葉を引き合いに出し、政策失敗の責任を専門家に転嫁しようとする政治家の醜悪さ、そして政府および役人の無謬性にこだわって、間違いを決して認めず、反省しようとしない官僚の非人間性と傲慢さが、見事に浮き彫りになっていて、無性に感情を揺さぶられます。
新型コロナウイルスに関心のある人だけでなく、専門知のあり方に関心のある人や、政治と科学と市民の関係に関心のある全ての人に、是非とも読んでいただきたい渾身の力作です。
- 1846. 「魔女・産婆・看護婦 女性医療家の歴史」 投稿者:杉本典夫 [URL] 投稿日:2021/06/12 (Sat) 17:29:41
- ・「魔女・産婆・看護婦 女性医療家の歴史(Witches, Midwives, and Nurses)」バーバラ・エーレンライク/ディアドリー・イングリッシュ共著/長瀬久子訳、法政大学出版局、1996年
1970年代のアメリカでパンフレットとして出版され、フェミニズムの古典となった「魔女・産婆・看護婦」と「女のやまい」を収めた初版に、その後の社会変化を解説した序文を加え、訳文も全面的に改めた増補改訂版です!(^o^)/
洋の東西を問わず、太古から医療は女性の役目であり、女性の生得権であり、女性の世襲財産の一部でした。ところが西欧では、中世に男性権力者(王侯とキリスト教会)がそれを奪い取り、男性中心の社会構造を作るために組織的に行ったものが魔女狩りであり、火炙りにされた魔女の大半は女性医療家――主に産婆でした。
そして女性医療者は主に農民階級の人達を治療していて、王侯や教会に反発する農民階級の人達の自治&反乱組織と深い関係がありました。つまり魔女狩りは、支配者階級にとって脅威であるそれらの組織活動を潰すためのテロ活動でもあったのです。
ところが、本来、医療行為には女性の方が適していて、男性ではうまく処理できない事が多々あります。そこで診断・治療・看護という医療行為のうち、男性医師は診断と治療(または治療方針の立案)だけを行い、治療の補助と、最も手間がかかる看護は、奉仕を自らの使命と考え、忍耐強く、どんな大変な汚れ仕事でも喜んで行う滅私奉公型の医療労働者――看護婦に押し付けました。
そして医療行為の手柄と報酬は男性医師が独り占めし、看護婦は手柄と報酬を主張する権利もなく、召使いとほとんど変わらない待遇になったのです。
若かりし頃、仕事の都合で医療分野に首を突っ込むようになって、一番驚いたのは、大学医学部の教授を頂点にして、医師・看護師・薬剤師・コメディカル等によって形成された専制君主型ヒエラルヒー社会の時代錯誤的な封建性でした。(そのヒエラルヒー社会の床下――決して「縁の下(の力持ち)」ではない!――でゴーレムのように蠢いていたのが、製薬業界の人達でした。(;_;))
本書を読んで、そんな専制君主型ヒエラルヒー社会が形成された歴史的背景がよくわかりました。
筆者達は本書の最後を次のような趣旨の文章で結んでいます。
「女性を抑圧しているのは生物学的な要素ではなく、性と階級に基づく社会制度だという事実を理解することが重要である。
そしてその理解に基づいて、社会的な選択肢を女性が管理する権利、現在そうした選択肢を決定している社会制度を管理する権利を求めて行動することが大切である」
フェミニズムや医療分野における性差別の歴史に興味のある人に、本書を強くお薦めします!v(^_-)
- 1845. Re[1844]:疫学と統計 投稿者:杉本典夫 [URL] 投稿日:2021/03/24 (Wed) 08:39:35
- >Annasさん
初めまして、当館の館長を努めている”とものり”こと杉本典夫です。
当館の「統計学入門」を読んでいただき、ありがとうございます。m(_ _)m
>>特に「線形混合モデル」に興味を持って調べていたのですが、
>>調べているうちに「繰り返しのある二元配置分散分析」などなど出てきて
>>更に混乱してしまい、見失ってしまいました。。
線形混合モデル(線形混合効果モデル)は流行りの手法ですが、僕はあまり評価していません。(^_^;)
その理由は「統計学入門」の次のページを読んでみてください。
○玄関>雑学の部屋>雑学コーナー>統計学入門
→12.9 時系列共分散分析 (注4)
http://www.snap-tck.com/room04/c01/stat/stat12/stat1209.html#note04
>>今後質問投稿させていただくことがあるかもしれませんので
>>その際はどうぞよろしくお願いいたします。
質問は大歓迎ですから、いつても気楽に質問してください。
当館ともども、よろしくお願いします。m(_ _)m
- 1844. 疫学と統計 投稿者:Ananas 投稿日:2021/03/24 (Wed) 01:24:21
- はじめまして、統計手法を調べていたらこちらのぺージにたどり着きました、栄養疫学の博士課程の学生です。博士課程を初めて半年です。コホート研究の経時的データの解析に関してどの手法が最も適しているのか考察中です。今とにかくわからないことだらけで???な中、かなり充実したページを見つけて驚いているところです。
私の研究はすでに測定されているデータの解析というものなので、「あるデータに最も適した統計手法を選ぶ」というのをとても難しく感じています。
特に「線形混合モデル」に興味を持って調べていたのですが、調べているうちに「繰り返しのある二元配置分散分析」などなど出てきて更に混乱してしまい、見失ってしまいました。。
今後質問投稿させていただくことがあるかもしれませんのでその際はどうぞよろしくお願いいたします。
- 1843. ワクチンの有効性と安全性 投稿者:杉本典夫 [URL] 投稿日:2021/03/16 (Tue) 16:57:29
- 当館の雑学コーナーに「ワクチンの有効性と安全性」を追加しました。(^o^)/
急性呼吸器症候群COVID-19用のワクチンが続々と開発され、その臨床試験の結果が公表されつつあります。そこでファイザー(Pfizer)とバイオンテック(BioNTech)が開発した、mRNAワクチンの臨床試験結果の論文について、主としてデータ解析部分を解説しました。
ワクチンに関心のある人は、ちらっと覗いてみて下さい。(^_-)
○玄関>雑学の部屋>雑学コーナー>ワクチンの有効性と安全性
http://www.snap-tck.com/room04/c01/vaccine/vaccine.html
- 1842. 致死率の誤差 投稿者:杉本典夫 [URL] 投稿日:2021/03/06 (Sat) 11:24:32
- 当館の雑学コーナーにアップしてある「感染症数理モデル」に、「致死率の誤差」を追加しました。(^o^)/
感染症で用いる感染率と死亡率の統計学的誤差(標準誤差)は、すでに計算方法が確立しています。しかし致死率の統計学的誤差については、あまり検討されていないと思います。感染率や死亡率と致死率は統計学的な性質が少し異なるので、その誤差について検討してみました。
感染症に関心のある人は、ちらっと覗いてみて下さい。(^_-)
○玄関>雑学の部屋>雑学コーナー>感染症数理モデル
→補足1.致死率の誤差
http://www.snap-tck.com/room04/c01/covid19/covid19051.html
- 1841. 「理論疫学者・西浦博の挑戦 新型コロナからいのちを守れ!」 投稿者:杉本典夫 [URL] 投稿日:2020/12/21 (Mon) 11:25:09
- ・「理論疫学者・西浦博の挑戦 新型コロナからいのちを守れ!」西浦博・川端裕人、中央公論社、2020年
帯のアオリ文句にあるように、”8割おじさん”こと西浦博先生が「科学者の社会的使命とは何か?」と自らに問いながら走り抜いた半年間の貴重な記録であり、西浦先生の追っかけをしている僕にとってバイブルになりそうな本です!(^o^)/
製薬企業の新薬開発プロジェクトや、厚労省の班研究や、AMED(日本医療研究開発機構)の統合プロジェクト等にデータ解析屋として関わった僕は、(これほど過酷ではありませんが(^^;))西浦先生と似たような仕事を経験しました。
データ解析屋は裏方ですから、表に出ることはめったにありません。ところが図らずも表舞台に引っ張り出されてしまった西浦先生は、それならばと、従来の父権主義的――paternalism、強い立場にある者が、弱い立場にある者の利益のためだとして、本人の意志は問わずに介入・干渉・支援すること――な政策決定ではなく、意思決定支援――risk informed decision、対策として考えられる全ての選択肢について、そのベネフィットとリスクの情報を全て公開した上で、政府または国民が主体的に意思決定するのを支援すること――による政策決定に挑戦しました。
その結果、脅迫状が届いたり、殺害予告を受けたりしながらも、果敢に挑戦し続け、現在も最良の方法を模索し続けられています。
COVID-19と科学コミュニケーションに関心がある、全ての人に読んでいただきたい本です。(^o^)/
- 1840. Re[1839]:回帰直線の信頼区間と予測区間 投稿者:杉本典夫 [URL] 投稿日:2020/05/23 (Sat) 08:56:41
- >マーシーさん
> 仕込量が0のときに、推定母集団の生成物量がとり得る区間(95%CI:0.082-0.178 99%CI:0.067-0.197)
> 仕込量が0のときに、サンプル集団の生成物量がとり得る区間(95%CI:0.041-0.220 99%CI:0.012-0.197)
信頼区間は、標本集団の値から母集団のパラメータを推定する手法です。そのため、標本集団に信頼区間はありませんよ。(^_^;)
上記の推定区間は、おそらく信頼区間と予測区間ではないかと思います。信頼区間は、標本集団の回帰直線から母集団の回帰直線を推定するものであり、信頼区間の間に母集団の回帰直線が95%の確率で入ります。
それに対して予測区間は、標本集団の回帰直線から母集団の個々のデータを推定するものであり、予測区間の間に母集団の個々のデータの95%が入ります。
> 「H0を棄却できないので、H1を採択するのを保留する」
> くらいの表現しか言えません。。。
> 有効性を言いたいはずなので、片側検定?ですよね
もう少し厳密に言うと、「H0を棄却できないので、結論を保留する」です。そして薬剤が疾患を悪化させることも考えられるので、通常は両側検定を用います。
このように、曖昧なデータから強引に結論を導くことは決して「科学的な態度」でありません。データから結論できる限界を明確にすることが、本当の「科学的な態度」です。そして科学的な結論には必ず限界があるので、常に最悪の状況を想定して行動することを「予防原則」といい、科学研究の成果を実践する時の重要な原則です。
検定について、詳しいことは次のページを見てください。(^_-)
http://www.snap-tck.com/room04/c01/stat/stat01/stat0105.html
- 1839. 無題 投稿者:マーシー 投稿日:2020/05/22 (Fri) 14:37:31
- http://www.snap-tck.com/room04/c01/stat/stat05/stat0501.html
5章。。。きっとわかりやすく書いてくださっているのに猛烈に難しい。すみません。
仕込量が0のときに、推定母集団の生成物量がとり得る区間(95%CI:0.082-0.178 99%CI:0.067-0.197)
仕込量が0のときに、サンプル集団の生成物量がとり得る区間(95%CI:0.041-0.220 99%CI:0.012-0.197)
と計算しました。
これらを以て、仕込みが0でも生成物は0になる確率は低いと言えそうです。N=89
統計屋さんってすごすぎます。
H0:アビガンと既存薬に差がない
H1:アビガンと既存薬に差がある
「H0を棄却できないので、H1を採択するのを保留する」
くらいの表現しか言えません。。。
有効性を言いたいはずなので、片側検定?ですよね
- 1838. Re[1837]:実務 投稿者:杉本典夫 [URL] 投稿日:2020/05/22 (Fri) 08:30:36
- >マーシーさん
> この回帰直線は仕込量と生成物量の予測に使えるでしょうか?
> y = 0.002x + 0.1307 R² = 0.5636
寄与率が約56%あるので、この回帰直線はある程度信頼できると思います。ただしこの回帰直線が仕込量と生成物量の予測に使えるかどうかは、回帰係数「0.002」が実質的に有意義かどうかを検討する必要があります。
この回帰係数から「仕込み量が1増えると、生成物量が0.002増える」と解釈できます。「仕込み量が1増える」ということが現実的に有り得て、「生成物量が0.002増える」ということに実質的な意義があれば、この回帰直線が仕込量と生成物量の予測に使えると考えられます。
しかし「仕込み量が1増える」ということが現実には有り得なかったり、「生成物量が0.002増える」ということが実質的に「生成物量が増える」とは言えない時は、この回帰直線は仕込量と生成物量の予測には使えないと考えられます。
例えばxが年齢で、yが身長(cm)だとすると、回帰係数が0.002ということは、年齢が100歳増えても身長は0.2cm増えるだけです。これでは、この回帰直線から身長を予測できるとは言えません。むしろ「年齢は身長に対して実質的に影響していない」と考えた方が適切です。
それと同様に、回帰係数が0.002ということが生成物量にほとんど影響しないのなら、「仕込みの有無にかかわらず、生成される」と考えた方が適切です。
以上、参考になれば幸いです。
- 1837. 実務 投稿者:マーシー 投稿日:2020/05/21 (Thu) 15:14:31
- 杉本さま
いつもお世話になっております。
今回、ある反応における物質の仕込量Xと生成物量Yのデータあります。
それらから回帰直線をエクセルで求めました
この回帰直線は仕込量と生成物量の予測に使えるでしょうか?
y = 0.002x + 0.1307�R² = 0.5636
仕込の有無にかかわらず、生成されることが言いたいのです。統計的に。
- 1836. Re[1835]:二項分布について 投稿者:杉本典夫 [URL] 投稿日:2020/05/13 (Wed) 08:33:36
- >マーシーさん
> http://www.wwq.jp/stacalcul/variance4.htm
> このサイトには
> 2項分布の分散は σ2=P(1-P)、標準偏差は σ=√{P(1-P)}となります。
このサイトの説明は割合(構成比)Pだけに着目していて、例数nのことを無視しています。
実際のデータでは例数nが関係するため、分散はP(1-P)/nになります。計算例の男45人、女35人の時の割合の分散は、実際にはP(1-P)/n=0.5625×(1-0.5625)/80=0.0030762になります。
nを無視すると、Pが同じなら分散が全て同じになってしまいます。しかし例数nが多いほど分散が小さくなり、Pの確実性が大きくなるのは当然です。そのためnを無視した分散の式は間違っていることが、感覚的にわかると思います。
インターネット上の情報は玉石混合ですから、こういう間違った説明をしているものがけっこうありますよ。実際、困ったもんです。(^_^;)
- 1835. 無題 投稿者:マーシー 投稿日:2020/05/12 (Tue) 09:23:10
- http://www.wwq.jp/stacalcul/variance4.htm
このサイトには
2項分布の分散は σ2=P(1-P)、標準偏差は σ=√{P(1-P)}となります。
二項分布は、分母の例数nが大きくなると、中心極限定理によって平均nπ、分散nπ(1-π) と矛盾する気がするのですが。。。
ダメだ、わからない。
統計学、再試験組だった私、大人になっても苦手なままです。。。
- 1834. Re[1832]:質問2 投稿者:杉本典夫 [URL] 投稿日:2020/05/08 (Fri) 08:42:40
- >マーシーさん
> 第1章6.4のサンプルサイズの計算式とで
> 同じ有意水準5% 検出力80% 検出差5 母標準偏差10 で計算してみると
第1章6.4のサンプルサイズの計算式は、1標本(1群)の場合の計算式です。2標本(2群)の場合の計算式は、次のページに記載してあります。
http://www.snap-tck.com/room04/c01/stat/stat01/stat0108.html#note01
上のページの「2.計量尺度・2標本の場合 (1)2標本の平均値の差の検定」の計算式を近似式にすると、紹介していただいたサイトの計算式になることがわかると思います。
2標本の場合の1群の必要例数は、1標本の場合の必要例数の約2倍になります。(^_-)
- 1833. Re[1831]:質問 投稿者:杉本典夫 [URL] 投稿日:2020/05/08 (Fri) 08:35:06
- >マーシーさん
お久しぶりですね!(^o^)/
> この正規分布Nの標本平均は(nπ,nπ(1-π)/n)という分布となる理解で正しいでしょうか?
> 標本平均の分散は母分散の1/nという理解をしています。
いえ、次のように二項分布の標本平均値(x/n)の期待値はπになり、標本平均値の分散は{π(1-π)/n}になります。
E(x/n)=E(x)/n=nπ/n=π V(x/n)=V(x)/(n2乗)=nπ(1-π)/(n2乗)=π(1-π)/n
その結果、二項分布の標本平均値はN(π,π(1-π)/n)という正規分布に近似します。
詳しいことは次のページをご覧ください。(^_-)
http://www.snap-tck.com/room04/c01/stat/stat03/stat0302_2.html#note02
- 1832. 質問2 投稿者:マーシー 投稿日:2020/05/07 (Thu) 17:23:25
- 杉本さま
重ねて質問ばかりすみません。
https://bellcurve.jp/statistics/blog/14304.html
上記サイトのサンプルサイズの計算式と
第1章6.4のサンプルサイズの計算式とで
同じ有意水準5% 検出力80% 検出差5 母標準偏差10 で計算してみると
必要症例数n=64
必要症例数n=33(補正2の場合 補正1なら31)
ちょうど半分になっており、大きく異なる理由が理解できません。
- 1831. 質問 投稿者:マーシー 投稿日:2020/05/07 (Thu) 11:31:32
- 杉本さま
お久しぶりです。統計の勉強にかなり間が空いておりました。。。
(異動による引っ越しやらで、QA業務に慣れるのに一苦労。泣)
早速です。
二項分布は、分母の例数nが大きくなると、中心極限定理によって平均nπ、分散nπ(1-π)の正規分布で近似できるのは理解できました。(ランダムデータ作成して実際にそうなることも確認しました)
近似した正規分布N(nπ,nπ(1-π))の標準誤差SEを求めたいのですが、自分の計算ではweb上の答えになりません。。。
この正規分布Nの標本平均は(nπ,nπ(1-π)/n)という分布となる理解で正しいでしょうか? 標本平均の分散は母分散の1/nという理解をしています。
結果、SE(標本平均の標準偏差)は √nπ(1-π)/n つまり √π(1-π) となると考えます。
しかし何かが間違っているようで、√π(1-π)/n が正しいとの事。
ご解説願えますでしょうか?よろしくお願いいたします。
- 1830. 感染症数理モデル-18 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:45:52
- 感染予防対策には、各国の自然環境と社会環境と国民性が大きく反映されます。各国の医療従事者の人達は、自国のそれらの要因を考慮して、試行錯誤しながら、最適と思われる感染予防対策を立て、まさしく命がけで実践しています。そのため他国の感染予防対策の中で、自国に応用できそうな部分を学ぶことは大切ですが――実際、各国の感染専門家達は定期的に連絡を取り、意見を交換し合っています――、色々な要因を考慮せずに、表面的な結果だけを見て対策の効果を比較するのは、あまり意味のあることではありません。
集団の背景因子(性別や年齢等)が異なれば、同じ疾患でも感染率と死亡率が異なるのは当然です。そのため医学分野では、色々な集団における疾患の発症率や死亡率を比較する時は、背景因子による補正をし、調整発症率や調整死亡率にしてから比較するのが常識です。その意味でCOVID-19の場合は、国と国の比較よりも、国ごとに、同じような性質のインフルエンザとか、スペイン風邪と比較する方が実際的です。
現在のところ、どの国も、COVID-19の感染率・死亡率ともに、インフルエンザ・肺炎の100分の1程度、スペイン風邪の1000分の1程度に抑えていて、奇跡的な成功を収めつつあると言って良いと思います。これに比べれば国と国の感染率のたかだか数倍の違いは、ほとんど誤差範囲です。
※「Preliminary In-Season 2019-2020 Burden Estimates」は、アメリカCDC(Centers for Disease Control and Prevention)のサイトから引用した、アメリカにおける今シーズンのインフルエンザの各種推定値です。インフルエンザの推定感染者数が3,900万人〜5,600万人であるのに対して、現在のCOVID-19累積感染者は約50万人ですから、約100分の1に抑えています。
- 1829. 感染症数理モデル-17 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:45:24
- 日本の次に、中国と韓国のCOVID-19のデータを解析してみました。これら2国は流行がほぼ終息しているので、簡易モデルを当てはめるのに都合が良いからです。中国については、すでに色々な研究者が解析結果を公表しているので省略して、韓国の解析結果について説明しましょう。
現在までのところ、韓国には主に2つの流行があるようです。1つ目は2020年1月20日に始まり、約60日後の3月下旬に収束しかかっていた流行です。3月下旬までのデータを用いて、この流行に簡易モデルを当てはめたところ、始まってから約80日後の4月上旬に、累積感染者数約1.64人/1万人(実数にして8,400人)に収束すると予想されました。
ところが3月下旬に新しい小規模な流行が始まり、それが現在は収束しつつあります。3月末までのデータを用いて、この2番目の流行に簡易モデルを当てはめたところ、始まってから約20日後の4月中旬に、累積感染者数約0.4人/1万人で収束すると予想されました。そして2つの流行を合わせて、4月中旬に累積感染者数約2.1人/1万人(実数にして約10,700人)にほぼ収束すると予想されました。
2つ目の流行は、1つ目の流行がほぼ終息し、緊張状態が緩んだことと、外国からの帰国者が多数いて、その中に感染者がいたことが原因ではないか、と考えられているようです。薬剤で言えばリバウンドに相当する、ほぼ終息後のこの小規模な流行は、今後、どこの国でも発生する可能性が高いと思います。
韓国はSARSや新型インフルエンザの感染予防の経験に基づいて、以前から遺伝子検査体制を整備していました。そのためCOVID-19の場合も、欧米と同じようなローラー作戦を取りました。そして幸か不幸か中国との間に北朝鮮という緩衝地帯があるので、半島でありながら島国のような環境です。そのため空港と港での検疫を徹底すれば、国境封鎖と同じような感染予防効果があります。
それと同時に、少しでも感染の疑いのある人がいれば迅速に検査して、偽陽性の人が多少含まれていようと、仔細かまわず隔離措置を行ったようです。その作戦が成功し、人口密度が高いにもかかわらず、流行が広がるスピードを緩めて、ほぼ終息後の累積感染者数を約2人/1万人(実数にして約10,000人)に抑えています。
- 1828. 感染症数理モデル-16 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:44:58
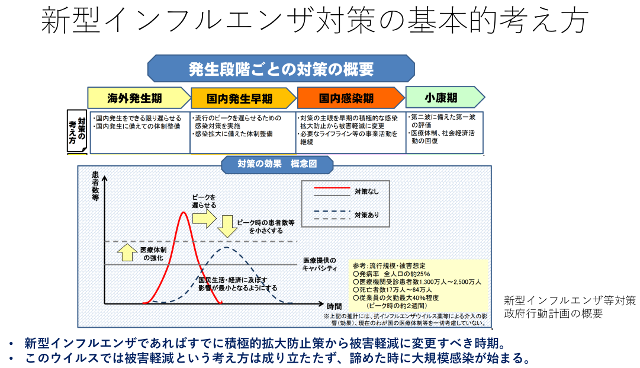
- 集団感染を起こした集団を迅速に発見し、その集団を隔離措置すると同時に、できるだけ「3密環境」を無くすことによって、γ(単位時間あたりの隔離率)を大きくし、β(単位時間あたりの感染率)を小さくして、R0(基本再生産数)を小さくすることができます。γを大きくし、βを小さくしてR0を小さくすると、流行がゆっくりと広がり、ゆっくりと納まります。
そのため下図「新型インフルエンザ対策の基本的考え方」のグラフのように、流行している期間は長くなりますが、ピーク時の感染者数を少なくして医療崩壊を防ぎ、流行終息時の累積感染者数を少なくすることができます。つまり欧米のようなローラー作戦ではなく、集団感染が発生するたび、患者集団をモグラ叩きのようにひとつずつ潰し、長期間のゲリラ戦に持ち込む作戦なのです。「感染症数理モデル-9」で示した日本の累積感染者数のグラフを見ると、現在のところその作戦が成功していて、流行の進行をゆっくりにし、ピークを後ろにずらしていることがわかると思います。
※図は、厚労省対策推進本部クラスター対策班の押谷仁先生が作成された、「COVID-19への対策の概念」から引用させていただきました。
- 1827. 感染症数理モデル-15 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:44:27
- 新型コロナウイルス感染対策専門家会議による、現在の基本的な感染予防対策は次のようなものです。
(1) 患者集団(cluster、集団感染を起こした小集団)の早期発見・早期対応
(2) 患者の早期診断・重症者への集中治療の充実と医療提供体制の確保
(3) 市民の行動変容
日本の場合、人口に対するPCR検査実施可能施設の割合が少ないため、欧米のように、少しでも感染の疑いのある人について、全てPCR検査を行う余裕はありません。そこで過去の新型インフルエンザ対策と同様に、全ての感染者を発見することは目指さず、他人に感染させる可能性の高い感染者と、重症になりそうな感染者を優先的に検査することにしたのです。
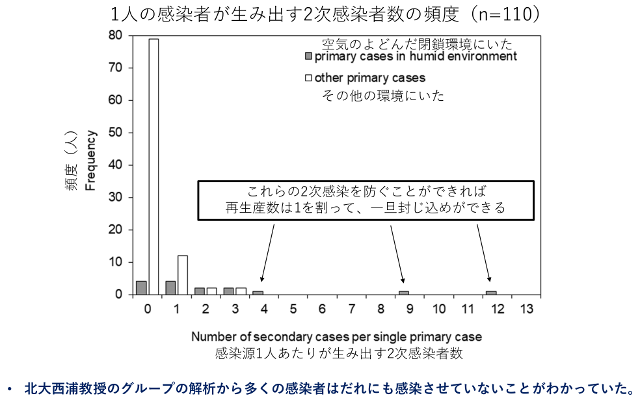
これまでの研究から、数理モデルにおける閉鎖集団の仮定に反して、全ての感染者が同じ頻度で2次感染を起こしているわけではないことがわかっています。下図「1人の感染者が生み出す2次感染者の頻度」に示したように、約80%の感染者は2次感染を起こさず、残りの約20%の人が2次感染を起こしていたのです。そして2次感染を起こした感染者は、大半が「空気のよどんだ閉鎖環境」つまり「3密(密閉・密集・密接)環境」にいました。そこで集団感染を起こした集団を迅速に発見し、その集団を隔離措置すると同時に、できるだけ「3密環境」を無くせば、2次感染を効率的に防げると考えたのです。
※図は、厚労省対策推進本部クラスター対策班の押谷仁先生が作成された、「COVID-19への対策の概念」から引用させていただきました。
- 1826. 感染症数理モデル-14 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:43:57
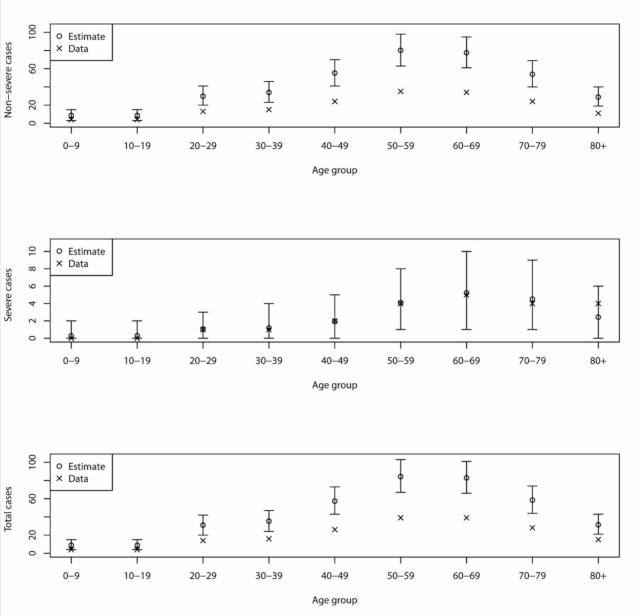
- 日本の感染者数の精度については、感染症数理モデルの専門家である西浦博先生達が、数理モデルを使って検討されています。その結果では、下図のように、重症者(Severe cases)は実測値と理論値がほぼ一致していて、軽症者(Non-severe cases)は実測値が理論値の半分程度になっています。これは、日本の医療従事者による重症例のトリアージが正確であることと、後述する日本の感染予防対策の特徴を表していると思います。
またクラスター対策班の徹底した調査によって、第1の流行は、ほとんどの感染源を中国までたどる――中国からの訪問者や帰国者等――ことができるのに対して、現在の第2の流行は、欧米由来の感染源――欧米からの訪問者や帰国者等――が多いことがわかっています。そしてクラスター対策班は、以前からこの第2の流行を予想していて、それに対する対応策(緊急事態宣言等)を検討していたとのことです。いずれにせよ、現在の第2の流行については、今後の動向を注意深く見守る必要があります。
※グラフは「Ascertainment rate of novel coronavirus disease (COVID-19) in Japan」(Ryosuke Omori, Kenji Mizumoto, Hiroshi Nishiura, Ascertainment in Japan, 2020)から引用させていただきました。
- 1825. 感染症数理モデル-13 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:43:27
- ダイヤモンド・プリンセスの次は、日本のCOVID-19のデータを解析してみました。マスコミなどは、ダイヤモンド・プリンセスの感染者を日本の感染者に含めて発表しています。しかしWHOの定義では、ダイヤモンド・プリンセスの感染者は「International」になっていて、日本の感染者に入れていません。また数理モデル上でも、ダイヤモンド・プリンセスは独立した特殊な閉鎖集団なので、日本とは別にした方が合理的です。
日本については、現在の第2の流行が始まる前だったので、あまり良い結果は得られませんでした。そしてその解析結果も、某医学研究者が論文に採用する可能性が高いので、残念ながらここでは公表できません。(^^ゞ
代わりに、
「日本はPCR検査件数が少ないので、見かけの感染者数が少ないだけで、本当はもっと流行している!」
という巷の噂を、簡易モデルを使って検討してみましょう。もしこの噂が正しいとすると、感染者が発見されず、単位時間あたりにI区間(感染者区画)からR区画(隔離区画)に移行する割合γが小さくなります。
例えば、実際には現在の感染者数の10倍の人数の感染者がいると仮定します。するとγは現在の10分の1になり、R0(基本再生産数)=β/γは10倍になり、感染初期のI(t)の変化を表す指数関数の係数(β-γ)は非常に大きくなります。そうすると、「感染症数理モデル-11」で説明した最終規模方程式「1-pi≒exp(-pi・R0)」から、流行終息時の感染者の割合が非常に多くなります。
またβ(単位時間あたりの感染率)とγは、最終的な割合ではなく、単位時間あたりの割合、つまり速度を表すパラメータです。そのため(β-γ)が大きくなれば、感染が広がる速度が速くなり、S区間の人数が急激に減るので、感染が納まる速度も速くなります。つまりS区画の感染すべき人が猛スピードで感染し、感染があっという間に広がったかと思うと、あっという間に終わってしまわけです。
そこで感染者数が現在の2倍、5倍、10倍存在し、現在の数の感染者しか発見できていないと仮定して、簡易モデルを当てはめてシミュレーションしてみました。それが下のグラフ「CFD/1万人」の「JP(感染者数2倍)」、「JP(感染者数5倍)」、「JP(感染者数10倍)」の赤い破線で描いた曲線です。これらの曲線から、流行が現在よりも早く始まり、それが猛スピードで広がり、猛スピードで収束することがわかると思います。
「CFD/1万人」のシミュレーション「JP(感染者数10倍)」は、2020年1月1日から約75日後の3月16日に、累積感染者数約20人/1万人、実数にして約254,000人(そのうち重症者は約50,000人)でほぼ収束しています。つまり、もし本当の感染者が現在の感染者の10倍いたとしたら、3月中旬に流行はほぼ終息していて、全国に約5万人の重症者が発生していたことになります。日本では重症者はほとんど見逃さずに見つけているので、さすがにこれは無いと思います。
また「JP(感染者数5倍)」も、3月下旬に累積感染者数約10人/1万人、実数にして約127,000人(そのうち重症者は約25,000人)でほぼ収束しています。重症者の推移から考えて、この可能性もかなり低いと思います。
「JP(感染者数2倍)」は、3月末に累積感染者数約3.2人/1万人、実数にして約40,640人(そのうち重症者は約8,100人)でほぼ収束しています。これも、重症者の推移が現在の重症者の推移と食い違っているので、可能性は低いと思います。
ただ4月になってPCR検査数を増やしているので、これまで見つかっていなかった感染者が見つかり、それが現在の第2の流行のように見えていると解釈することは、一応、可能です。その場合、実際の流行はほとんど収束しているので、検査数が増えるに従って見つかる感染者が一気に増え、現在いる感染者を全て検査し終われば、見つかる感染者が一気に減るはずです。でも現在のところ、1日あたりの感染者の変化は、数理モデルから予想される変化とだいたい一致していて、不自然な変化はありません。
- 1824. 感染症数理モデル-12 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:42:54
- ダイヤモンド・プリンセスでは、流行終息時の感染率は約19%でした。「流行強度(最終規模)のR0応答」グラフで、pが0.19の時のR0を見ると、だいたい1.1くらいです。そしてR0=1.1から、I(t)がピークになる時の感染率piを求めると、次のようになります。
pi=1 - 1/1.1≒0.09
ダイヤモンド・プリンセスの1日あたりの感染者数がピークになったのは、2月15日前後つまり最初の感染者が発見された時から約10日後であり、その時の累積感染率は約10%ですから、確かに辻褄が合っています。
ダイヤモンド・プリンセスでは、最初の感染者が発見される前のRtは、だいたい15くらいだったと推測されています。そして最初の感染者が発見され、検疫・隔離処置がされてから、約10日後に1日あたりの感染者数がピークになりました。COVID-19の潜伏期間と、検査が確定するまでの期間を合計すると10日ほどです。そのため検疫・隔離処置により、その後の新たな感染者は無くなって、Rtはほぼ0になり、約10日後に感染者が減り始め、流行が終息した時には約19%の人が感染し、流行全体の平均R0は1.1程度になった、と考えられます。
ダイヤモンド・プリンセスについては、「COVID-19製造機!」とか、「検疫・隔離措置の失敗!」などと、マスコミが煽り立てました。しかしデータを詳細に分析すると、検疫・隔離措置は見事に成功していて、何もしないでおいたらほぼ全員が感染したところを、検疫・隔離措置によって流行終息時の感染率を約19%に抑えられた、ということがわかります。(^_-)
- 1823. 感染症数理モデル-11 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:42:15
- ダイヤモンド・プリンセスのデータは、数理モデルを当てはめるのに適しているので、少し詳しく説明しましょう。このクルーズ船では、2020年2月5日に最初の感染者が発見され、2月15日前後に1日あたりの感染者数がピークになり、2月27日に流行が事実上終息しました。最終的な累積感染者数は696人/3,777人=約1,876人/1万人で、約19%の人が感染しました。
「感染症数理モデル-4」で説明したように、感染の初期段階では、I(t)つまり1日あたりの感染者が指数関数的に増加し、すこし経つと爆発的患者急増(overshoot)段階になります。しかし、それに応じて感染者が増え、S(t)つまり未感染者が減るため、I(t)の増加速度は次第に遅くなり、やがてピークを経てから減少し始め、最終的に流行は自然に終息します。I(t)がピークになる条件は、次の微分方程式から求めることができます。
・I区画の変化速度:vi=dI(t)/dt=β・S(t)・I(t)-γ・I(t)
I(t)の変化速度vi=0になる時、I(t)がピークになるので、
vi=dI(t)/dt=β・S(t)・I(t)-γ・I(t)=0 → β・S(t)-γ=0
ここでS(0)=1とし、時点tにおける感染者の割合をpiとすると、
β・S(t)=β(1-pi)=γ → 1-pi=γ/β=1/R0 → pi=1-1/R0
R0=β/γ:基本再生産数(1人の感染者が隔離・回復・死亡するまでの間に、何人の人を感染させたかを表す値)
このことから、感染者の割合piが(1-1/R0)になった時、I(t)がピークになり、その後は次第に減少することがわかります。このpiのことを、「臨海免疫化割合」と呼ぶことがあります。例えばR0=2の時は次のようになり、感染者の割合が50%になった時、1日あたりの感染者数がピークになり、その後は減少します。
pi=1 - 1/2=0.5
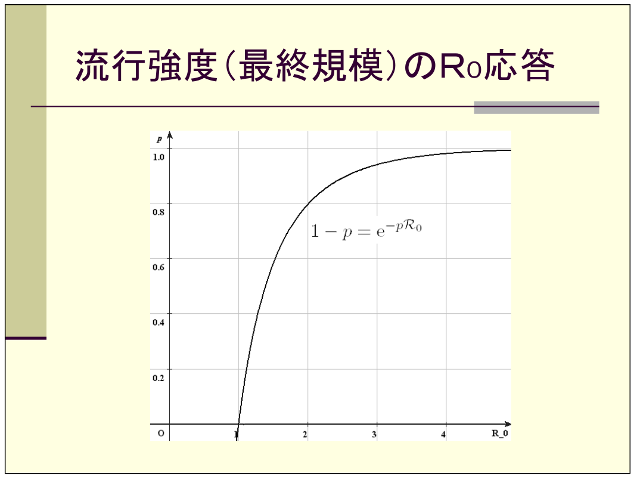
一方、S(t)は、癌の解析に用いられる生存時間解析に登場する、累積生存率関数S(t)とよく似た変化をします。そこで、S(t)が近似的に指数関数的に減少すると仮定すると、流行終息時の感染者の割合は、近似的に次のようになります。この式を「最終規模方程式(Final size equation)」といい、これをグラフ化したものが、下図の「流行強度(最終規模)のR0応答」です。
1-pi≒exp(-pi・R0)
∴pi≒1-exp(-pi・R0)
世界各地のデータから、COVID-19のR0はだいたい2前後と考えられています。そこで「流行強度(最終規模)のR0応答」グラフで、R0=2の時のpを見ると約0.8です。つまりR0=2(1人の感染者が2人の人を感染させる)の時、集団の50%の人が感染した時、1日あたりの感染者がピークになり、80%の人が感染すると流行が終息する、ということになります。
COVID-19について、「感染予防対策を何もしない時、全人口の60〜80%が感染して免疫を持てば、流行が終息する」という予想を、どこかで目にしたことがあると思います。この予想は、上記の数式から導かれたものです。
これを日本に当てはめると、累積感染者数が約6,350万人になった時、1日あたりの感染者数がピークになり、1億160万人になった時、流行が終息するという、恐ろしいことになります。世界中の感染専門家が、COVID-19を恐れた理由がわかると思います。
※上図の「流行強度(最終規模)のR0応答」は、東京大学大学院・数理科学研究科・稲葉寿教授の、「感染症の数理」から引用させていただきました。
- 1822. 感染症数理モデル-10 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:41:36
- COVID-19の現状分析をした後、まず最初にクルーズ船「ダイヤモンド・プリンセス」のデータに、考案した簡易モデルと開発中の統計解析手法を適用してみました。ダイヤモンド・プリンセスは閉鎖集団に近く、しかも流行が始まってから終わるまでの、ほぼ完全な観測データが得られています。そのため、すでに色々な研究報告が公表されていて、それらの結果と僕の解析結果はよく似ていました。でも残念ながら、その解析結果は某医学研究者が論文に採用する可能性が高いので、ここでは公表できません。(^^ゞ
代わりに、1万人あたりの累積感染者数の推移を「DP(人口3777人)」としてグラフ化しておきます。対照集団として、中国湖北省の1万人あたりの累積感染者数のグラフを入れておきました。「感染症数理モデル-9」のグラフの縦軸のスケールを100倍にしたので、中国湖北省のグラフはほとんど変化がないように見えてしまいます。日本のインフルエンザについて同じようなグラフを描くと、1年間の累積感染者数が約787人/1万人のところまで上昇します。
- 1821. 感染症数理モデル-9 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:40:59
- 感染症予防対策のうち、β(単位時間あたりの感染率)を小さくする対策は、インフルエンザに対しても有効です。そのため今年のインフルエンザの感染者数は、例年の50〜60%程度に減ると予想されています。しかしインフルエンザ患者は、普通は隔離措置をしないため、γ(単位時間あたりの隔離+回復+死亡率)は例年通りです。それに対してCOVID-19感染者は迅速に隔離措置をするため、γが大きくなります。
COVID-19はワクチンがなく、免疫を持っている人はいないと考えられています。事実、感染者の隔離措置が遅かった、ダイヤモンド・プリンセスの累積感染者数は約1,876人/1万人であり、インフルエンザの1年間の累積感染者数約787人/1万人の2倍以上の感染率です。
ところが、現在の世界各国のCOVID-19の累積感染者は、平均約10人/1万人程度であり、日本のインフルエンザ感染率よりも2桁近く少ない人数です。これは世界各国の医療従事者の懸命の努力と、民衆の自助努力の賜物です。現在までのCOVID-19感染者の推移は、おそらく感染症の歴史でも稀な奇跡的な現象であり、今はその奇跡を目の当たりにしている最中だと、僕は思っています。
世界各国の医療従事者の方々に、あらためて心からの敬意の念を表したいと思います。
- 1820. 感染症数理モデル-8 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:40:27
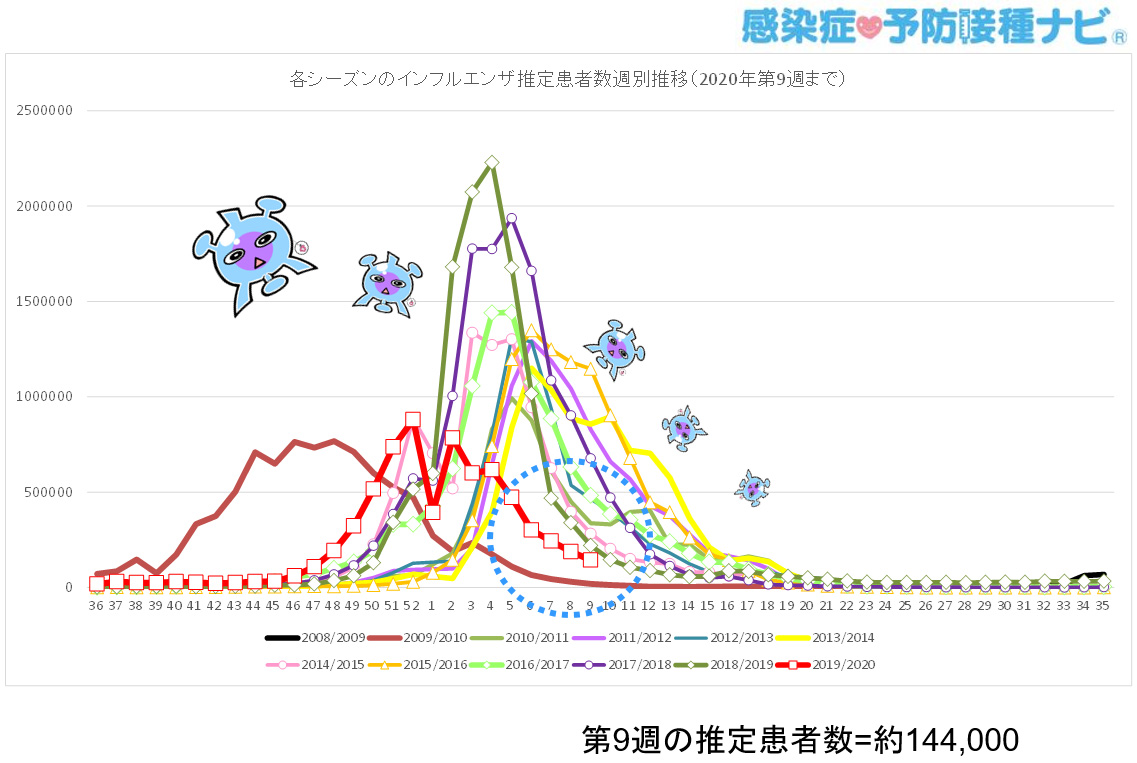
- 日本のインフルエンザの累積感染者数は、1年間で約1,000万人/12,700万人であり、1万人あたり約787人になります。参考までに、「感染症・予防接種ナビ」サイトで見つけた、「各シーズンのインフルエンザ推定患者数週別推移(2020年第9週まで)」の流行曲線をアップしておきます。このグラフは実数で描いてあるので、このグラフの縦軸を12,700で割れば、1万人あたりの1週間分のインフルエンザ感染者数になります。
例えば2018/2019年のピーク時である第3週は、約220万人/12,700万人=約173人/1万人になり、2019/2020年の流行が終わりかかっている第9週は、約144,000人/12,700万人=約11人/1万人になります。そして日本におけるインフルエンザの死亡率は約0.1%ですから、1週間あたりの死亡者は、それぞれ約2,200人と約144人と推測されます。
また1918〜1920年に大流行した有名なスペイン風邪は、3年間で約5億人が感染し、約5,000万人が死亡しました。当時の世界人口は約20億人ですから、3年間の累積感染率は約2,500人/1万人で、死亡率は約250人/1万人です。それに対して、COVID-19の3ヶ月間の累積感染率は約150万人/77億人=約2人/1万人で、死亡率は約9万人/77億人=約0.1人/1万人と、どちらも1000分の1ほどの人数です。
- 1819. 感染症数理モデル-7 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:39:46
- SIRモデルは大変有用ですが、あくまでもモデルのため、自ずと限界があります。その限界というか、問題点としては、次のようなものがあります。
(1) 現実の集団は閉鎖集団――人の出入りが無く、かつ質が均一な集団――ではない!
(2) βとγを正確に推測するためには、流行が始まってから終わるまでの完全な観測データが必要である!
→感染の流行中に、今後の動向を正確に予想することが難しい!
(1)の問題点については、不均一な1つの集団を、均一な複数の亜集団(Subpopulation)に分けて、それらの亜集団を対象にしてモデルを組み立てることが考えられます。これをマルチタイプ型流行(Multitype epidemic)モデルといいます。これはモデルが複雑になるので、解析手法も結果の解釈も複雑になりますが、より現実に近い結果が得られます。
ただし単一集団でも亜集団でも、対象集団について、人の出入りをできるだけ無くして、閉鎖集団に近づける必要があります。その対策の例として、国境の閉鎖や都市封鎖が考えられます。これらの対策の主目的は、もちろん感染予防です。しかし数理モデルを利用して流行の現状分析をしたり、今後を予想したり、対策を検討したりする時にも、現実の集団をできるだけ閉鎖集団に近づけることは大切です。
(2)の問題点についても、色々な対応策が考えられています。僕が考案した簡易モデルも、そのひとつです。SIRモデルを色々といじっていた時、モデルを簡単にし、パラメータ数を減らせば、微分方程式が簡単になり、近似解が得られることに気が付きました。これは薬物動態学でもよくやることなので――まだ感染症分野の文献を検索していませんが――すでに気付いた人がいると思います。
そしてその近似解に、某医学研究者が開発し、現在、僕が数学的な理論付けを手伝っている、新しい統計解析手法を適用すれば、流行の初期〜中期段階で、今後の推移をある程度予想できることがわかりました。そのことを某医学研究者に知らせたところ、作成中の論文の考察部分に入れたいので、具体例を解析して欲しいと依頼されました。
そこでインターネットを検索し、WHOが公表しているCOVID-19に関するデータをダウンロードして、COVID-19に関する現状分析をしました。まず個人的に興味のある国の1万人あたりの累積感染者数の推移を、3月末までのデータを用いてグラフ化しました。マスコミなどは、危機感を煽るために感染者数を実数で発表します。しかし医学分野では、流行の実態を正確に把握するために、感染者数を対象集団の人口で割り、感染率または1〜10万人あたりの感染者数で表現します。
医療機関では、PCR検査だけでなく、CT等の検査と、色々な臨床症状を総合的に検討して、最終的に感染者かどうか判断しています。ところがマスコミが発表しているのは、たいてい速報として発表されるPCR検査陽性者です。PCR検査の特性として、偽陽性者や偽陰性者が発生するため、検査の陽性率は、検査対象集団の感染率よりも少し高くなります。そのためマスコミが発表している感染者数――実際にはPCR検査陽性者数――は、厚労省やWHOが発表している確定感染者数よりも20〜30%多くなります。感染症数理モデルの解析に用いるデータは、当然、感染が確定した人のデータでなければなりません。そこで僕は、WHOのデータを用いて解析しています。σ(^_-)
グラフ「CFD/1万人」を見ると、イタリア(IT)が約17人/1万人で、この中では累積感染率が最も高くなっています。そして中国(CN)湖北省、ドイツ(DE)、アメリカ(US)、オーストラリア(AU)、韓国(KR)、日本(JP)の順になっています。通常、β(単位時間あたりの感染率)は人口密度に比例して大きくなります。そのことを考慮すると、どちらも人口密度が高い韓国と日本の累積感染率の低さは驚きです。
なお中国(CN)については、解析対象を湖北省だけに限っています。中国政府は、流行後、すぐに武漢の都市封鎖をしたので、湖北省を準閉鎖集団として扱うことができて便利だからです。
またクルーズ船「ダイヤモンド・プリンセス」は、最も閉鎖集団に近く、しかも流行が始まってから終わるまでの、ほぼ完全な観測データが得られています。そのため、数理モデルを当てはめるのに最適です。しかしダイヤモンド・プリンセスの累積感染者数は696人/3,777人、つまり約1,876人/1万人になり、このグラフと同じスケールでは描けません。
※現在のWHOのCOVID-19サイトは、以前、僕がダウンロードして用いたものとは形式が少し異なっています。でも、参考までに紹介しておきます。
https://who.sprinklr.com/
※こちらのECDC(European Centre for Disease Prevention and Control)のデータは、以前のWHOと同じ形式のデータです。このデータも、ダウンロードして解析に使っています。(^_-)
https://www.ecdc.europa.eu/en/publications-data/download-todays-data-geographic-distribution-covid-19-cases-worldwide
- 1818. 感染症数理モデル-6 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:39:05
- βとγは、多くの観測データを用いて、統計学的に求める必要があります。しかし「1人の感染者が隔離(または回復または死亡)するまでの間に、何人の人を感染させたかを表す値」は、発見された感染者の行動を詳細に調べ、その人と接触した人が感染したかどうかを調べれば、ある程度はわかります。そのため、ある時点tにおいて、この方法で求めたR0のことを「効果的再生産数Rt(Effective reproduction number)」と言います。Rtは時点tごとに変化する値であり、流行が始まってから終わるまでの間のRtを平均するとR0になります。
感染の初期段階で、I(t)の観測データを用いてポアソン回帰分析などで(β-γ)を求め、感染者の行動からRtが求められれば、次のようにしてβとγの推測値を求めることができます。
Rt=β/γ → β=Rt・γ
(β-γ)=a ← I0・exp{(β-γ)t}=I0・exp(a・t)より
(Rt・γ-γ)=(Rt-1)γ=a → γ=a/(Rt-1) → β=a+γ
これらの推測値を使うと、感染の初期段階でS(t)、I(t)、R(t)の今後の推移を予想することができます。そしてその予想に基づいて、感染予防対策を色々と検討することができます。
このように感染症数理モデルと疫学的調査を併用すると、合理的な感染予防対策を検討することができます。その具体的な内容は、厚労省対策推進本部クラスター対策班の押谷仁先生が作成された、「COVID-19への対策の概念」を御覧ください。(^_-)
https://www.jsph.jp/covid/files/gainen.pdf
I(t)の近似関数の両辺を対数変換すると、次のように1次式(直線)になります。
・ln{I(t)}≒ln(I0) + (β-γ)t
そこでI(t)を対数変換して直線回帰分析を行えば、回帰係数(β-γ)を求められると考えがちです。しかしI(t)はカウントデータ(count data)ですから、「0(感染者なし)」というデータがあり、これが重要な意味を持ちます。そのためI(t)を対数変換して、直線回帰分析を行うのは不適切です。このような場合は、ポアソン分布と最尤法を利用した、ポアソン回帰分析を適用する必要があります。ポアソン回帰分析については、僕のウェブサイトの次のページをご覧ください。(^_-)
http://www.snap-tck.com/room04/c01/stat/stat15/stat1501.html
言わずもがなの蛇足ですが、上記の説明から、今後の感染者数の推移を予想するには、βとγを推測する必要があることがわかると思います。しかしβとγを正確に推測するには、流行が始まってから終わるまでの感染者数の推移データが必要です。感染の初期段階では、(β-γ)のラフな推測値しか得られません。でも感染者の行動を詳細に調べて、Rtを推測することができれば、初期段階でもβとγのラフな推測値が得られます。
ところが僕を含めて一般のデータ解析屋が、Rtを推測することはほとんど不可能です。そのため、どうしても(β-γ)のラフな推測値から、今後の感染者数の動向を予測することになります。つまりRtのデータを持っていないデータ解析屋が予想した、今後の感染者数の推移予想は、僕のものも含めてσ(^^;)、あまり信用できないということです。日本でRtのデータを持っているのは、現在のところ、「新型コロナウイルス感染症対策会議」だけなのです。
- 1817. 感染症数理モデル-5 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:38:23
- 閉鎖集団で感染症が流行するかどうかは、感染の初期段階でI(t)を経時的に観測し、そのデータを用いて、例えばポアソン回帰分析などで係数(β-γ)を求めればわかります。(β-γ)は「単位時間あたりの感染率と隔離率の差」であり、「単位時間あたりに隔離される割合よりも、感染する割合の方が多ければ流行する」と解釈できます。しかしこの解釈は確率的であり、普通の人にはわかりにくいと思います。そこで、次のような値を定義します。
・基本再生産数(basic reproduction number):R0=β/γ
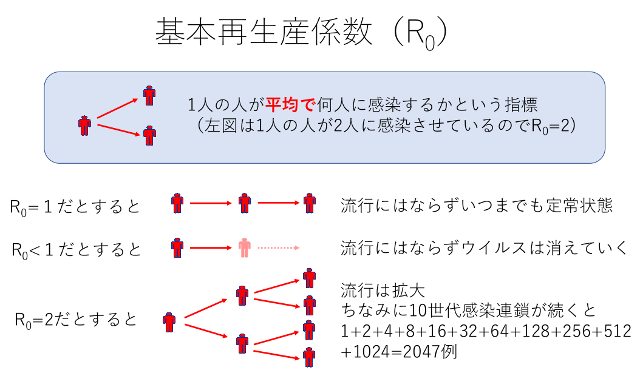
このR0(R noughtと発音)は、「単位時間あたりの感染率と隔離率の比」を表します。でもこれも普通の人にはわかりにくいので、
「1人の感染者が隔離(または回復または死亡)するまでの間に、何人の人を感染させたかを表す値」
と解釈すると、わかりやすいと思います。つまり1人の感染者が、隔離されるまでの間に、1人よりも多い人を感染させていれば流行が始まるわけです。この様子は、やはり「COVID-19への対策の概念」の、次の図「基本再生産係数(R0)」を見るとわかりやすいと思います。(^_-)
- 1816. 感染症数理モデル-4 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:37:40
- SIRモデルにおいて、S区画の最初の人数を1とすると、このモデルは割合または確率モデルになり、どんな人数の閉鎖集団についても当てはまる、一般的なモデルになります。そして最初の感染者が閉鎖集団に侵入または発生した時をt=0とすると、S(0)=1、I(0)=I0(初期感染者率、0<I0≪1)、R(0)=0になります。
この一般化したSIRモデルでは、感染の初期はS(t)≒1のため、I区画の微分方程式は次のように近似できます。
vi=dI(t)/dt=β・S(t)・I(t)-γ・I(t)≒β・I(t)-γ・I(t)=(β-γ)I(t)
この近似微分方程式の解は指数関数になり、次のような性質があります。
・I(t)≒I0・exp{(β-γ)t}
(β-γ)>0の時:I(t)は指数関数的に増加
(β-γ)=0の時:I(t)はI0のまま一定
(β-γ)<0の時:I(t)は指数関数的に減少
つまりI(t)はβとγの大小関係によって、指数関数的に増加したり、指数関数的に減少したりと、対照的な挙動をします。このような現象のことを、閾値現象(threshold phenomena)といいます
閉鎖集団における感染の初期段階では、「(β-γ)>0」つまり「β>γ」の時、I(t)が指数関数的に増加し、感染症が流行し始めます。I(t)は指数関数的に増加するので、最初のうちは流行に気が付きませんが、次第に加速していき、ある時、突然――と、普通の人には思えます(^^;)――急激に増加して大流行します。この段階のことを、「爆発的患者急増(overshoot)」といいます。
この爆発的患者急増段階の前に、何らかの感染予報対策を実施し、(β-γ)<0にすることができれば、I(t)は指数関数的に減少し、流行は終息します。(β-γ)<0にするためには、例えば次のような対策が考えられます。
・β(単位時間あたりの感染率)を小さくする → 人と人が接触する機会を減らす
・γ(単位時間あたりの隔離率)を大きくする → 感染者を素早く見つけ出し、素早く隔離する
この様子は、厚労省対策推進本部クラスター対策班の押谷仁先生が作成された、「COVID-19への対策の概念」の中の、次の図「接触を避けることによる流行拡大防止効果」を見るとわかりやすいと思います。(^_-)
- 1815. 感染症数理モデル-3 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:37:02
- 「感染症数理モデル-2」で説明した仮定から、SIRモデルにおいて、単位時間あたりの各区画の増減人数を各区画の変化速度vと考えると、次のような微分方程式が成り立ちます。
・S区画の変化速度:vs=dS(t)/dt=-β・S(t)・I(t) … S区画の人は単位時間あたりβ・S(t)・I(t)だけ減少する
・R区画の変化速度:vr=dR(t)/dt=γ・I(t) … R区画の人は単位時間あたりγ・I(t)だけ増加する
・I区画の変化速度:vi=dI(t)/dt=-vs-vr=β・S(t)・I(t)-γ・I(t) … I区画の人は単位時間あたり{β・S(t)・I(t)-γ・I(t)}だけ増加(β・S(t)・I(t)>γ・I(t))、または減少(β・S(t)・I(t)<γ・I(t))する
これらの連立常微分方程式を解けば、時間tによる各区画の人数の変化を表す関数S(t)、I(t)、R(t)を決定することができます。しかしこれらの連立常微分方程式はS(t)、I(t)、R(t)に関して線形ではないので、解析的に解くのは困難です。そこで普通は、直接観測することができるI(t)とR(t)の時系列データを用いて、ルンゲ・クッタ(Runge-Kutta)法などの数値計算手法によって近似的に解いたり、I(t)を特定の確率分布――例えばポアソン分布や対数正規分布――で近似し、それに基づいてS(t)とR(t)を決定して、最尤法などの確率論的な手法を使って近似的に解いたりします。
そのようにして近似的に解いた結果に基づいて、βとγの値を色々と変えた時のS(t)、I(t)、R(t)の値をプロットすると、色々な場合を想定した時の感染者数の推移をシミュレーションすることができます。
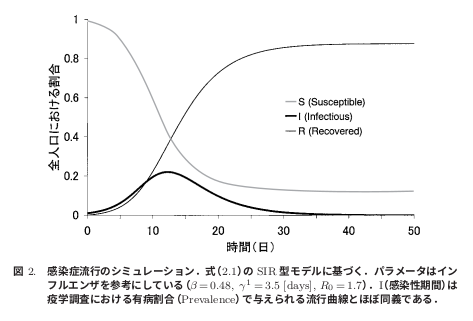
図2は、インフルエンザの解析結果を参考にして、β=0.48、γ=0.29(1/γ=3.5)、R0=β/γ=1.7の時の感染者の推移をシミュレーションしたものです。このグラフを見ると、S(t)、I(t)、R(t)の形が何となくわかると思います。そしてI(t)のグラフは、疫学調査で用いられる感染症の流行曲線――1日あたりの感染者数を時系列的にプロットしたグラフ――とほぼ同じものになります。
ちなみに、上記の連立常微分方程式における比例定数βとγは、単位時間あたりの率(rate)を表し、[1/単位時間]という単位を持ちます。このような比例定数は、感染症モデルだけでなく、薬物動態モデルでも、放射性元素の崩壊モデルでも登場し、速度定数(rate constant)とか、崩壊定数(decay constant)とか、時定数(time constant)などと呼ばれています。
※図2は、「感染症流行の予測:感染症数理モデルにおける定量的課題」西浦博、稲葉寿、統計数理(2006)・特集「予測と発見」から引用させていただきました。
- 1814. 感染症数理モデル-2 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:36:17
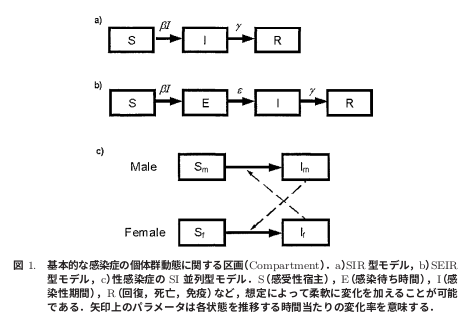
- 一般的な感染症数理モデルでは、閉鎖集団(Closed population、人の出入りが無く、かつ質が均一な集団、閉鎖人口ともいう)について、図1のa)ような区画モデルを想定します。この区画モデルのことを、提唱者の名前から「ケルマック−マッケンドリック型モデル(Kermack McKendrick model)」と呼んだり、各区画の頭文字を取って「SIRモデル(Susceptible-Infectious-Recovered model)」と呼んだりします。
○S(Susceptible)区画:未感染で、感染する可能性のある集団
○I(Infectious)区画:感染していて、感染性(他人を感染させる能力)のある集団
○R(Recovered)区画:感染後に隔離された者と、隔離せずに回復して免疫を獲得した者と、隔離せずに死亡した者の集団(感染性のない集団)
ここで、それぞれの区間について次のような仮定をします。
・単位時間(通常は1日)あたり、I区画の人がS区画の人を感染させる確率はβである。(0≦β、単位時間あたりの感染率)
※この仮定から、ある時間tにおけるI区画の人数をI(t)と書くと、「β・I(t)」のことを「時間tにおける感染力(force of infection)」と言います。
この感染力が大きいほど、S区間の多くの人を感染させます。そしてある時間tにおけるS区画の人数をS(t)と書くと、単位時間あたりの感染者数は「β・S(t)・I(t)」になり、この人達がS区画からI区画に移行します。
・単位時間あたり、I区画の人が隔離または回復または死亡する確率はγである。(0≦γ、単位時間あたりの隔離+回復+死亡率)
この仮定から、時間tにおける単位時間あたりの隔離+回復+死亡者数は「γ・I(t)」になり、この人達がI区画からR区画に移行します。
※図1は、「感染症流行の予測:感染症数理モデルにおける定量的課題」西浦博、稲葉寿、統計数理(2006)・特集「予測と発見」から引用させていただきました。
- 1813. 感染症数理モデル-1 投稿者:杉本典夫 [URL] 投稿日:2020/04/14 (Tue) 17:35:26
- 今、巷で話題のCOVID-19に関連して、感染症数理モデルについて勉強しました。恥ずかしながら、これまでに風邪やインフルエンザ等の簡単な臨床研究のデータ解析をやったことはありますが、感染症の数理モデルを本格的に扱ったことはありませんでした。そのため、この分野の専門家である西浦博先生と稲葉寿先生の文献をインターネットで検索し、次のような論文を探し当てました。
この論文を読んだところ、感染症数理モデルは、区画モデル(compartment model)を用いていることがわかりました。区画モデルは薬物動態学分野でも用いられていて、元製薬業界でメシを食っていて、薬物動態学のデータをいつも扱っていた僕にとっては、お馴染みのものです。σ(^_-)
そこでせっかく勉強したので、自分の覚書を兼ねて、感染症数理モデルと、それを応用したCOVID-19感染者推移について、概略を説明したいと思います。
https://www.ism.ac.jp/editsec/toukei/pdf/54-2-461.pdf
※薬物動態学で用いられる区画モデルについては、僕のウェブサイトの次のページを参考にしてくだい。(^_-)
http://www.snap-tck.com/room04/c01/stat/stat14/stat1401.html
- 1812. 家庭内LANサーバー 投稿者:杉本典夫 [URL] 投稿日:2020/02/05 (Wed) 11:02:12
- 近頃、家庭内LANサーバーにしている古い自作PCのハードウェアと、OSであるFedoraとの相性が悪くなり、不安定になっていました。そこで思い切ってOSをDebianに変更しました。
FedoraなどのRedHat系は先進性を重視しているのに対して、Debian系は安定性を重視しています。そのため古いハードウェアとの相性は良く、今のところ安定して作動しています。またメインマシンのOSがDebianから派生したUbuntuなので、メインマシンとの相性も良く、しばしば起きていたネットワーク関連のトラブルはまだ発生していません。
これからしばらくの間、このシステム構成で様子を見ることにします。v(^_-)
- 1811. Re[1810]:サンブル数の計算式について 投稿者:杉本典夫 [URL] 投稿日:2019/08/20 (Tue) 09:31:16
- >マーシーさん
>>統計の塾とか先生(大人ver)ってないものですかね、学校ってありがたいものだったのだなぁとしみじみ感じます。
ありますよ。僕は地元の名古屋で、寺子屋「統計庵」という小規模なセミナー活動を不定期に行っています。またセミナー会社の情報機構から依頼されて、半年に1度位のペースで統計学セミナーを行っています。その統計学セミナーについては、当館の次のページに記載してありますよ。(^_-)
○【出版物とセミナーのお知らせ】
http://www.snap-tck.com/room05/room05.html
>>1章の最後の方で、サンプル数の計算式がありますが、ここが難解です。
この計算式が理解できれば、統計的仮説検定はほぼ理解できますし、統計的仮説検定がしっかりと理解できれば、この計算式は自然と理解できるはずです。そのため、このページをじっくりと読んでみてください。(^_-)
- 1810. Re[1809]:[1808]:有病率の信頼区間について 投稿者:マーシー 投稿日:2019/08/19 (Mon) 21:16:22
- 小学生の頃、関数で直線の傾きを「変化の割合」と学習しましたが、正確には「変化率」なのですね。(微分のときも同じように習いました)
統計の塾とか先生(大人ver)ってないものですかね、学校ってありがたいものだったのだなぁとしみじみ感じます。そういう意味でとてもyoutube貴重です。
1章をしっかり読み込み、根本を理解しながら進んでいきたいと思います。
1章の最後の方で、サンプル数の計算式がありますが、ここが難解です。
- 1809. Re[1808]:有病率の信頼区間について 投稿者:杉本典夫 [URL] 投稿日:2019/08/16 (Fri) 12:16:37
- >マーシー様
>>母比率の推定として計算するのと、有病率の数値の母平均の推定として計算するのでは、結果は異なるのでしょうか?
これらは用語の違いであり、結果的には同じになります。
「統計学の基礎」の「3.3 差と比の使い分け」の最後に書いたように、比(ratio)と割合(proportion)と率(rate)はそれぞれ定義が異なる別物です。そして日本語では、これら3種類のものを全て「比率」というまぎわらしい用語で呼ぶことがあります。ご紹介いただいたyoutube動画は、これらのまぎわらしい用語を用いた典型的な「まぎわらしい統計学解説」です。(^_^;)
有病率は「分子が分母に含まれる分数」ですから、「疾患の割合」になり「率」ではありません。しかし「割合」という用語は研究現場では馴染みが薄いので、僕は致し方なく「有病率」をそのまま用い、一般化する時は「出現率」という用語を用いることにしています。ご紹介いただいたyoutube動画では、これを「比率」という用語で説明しています。「比率」は本来は「割合」であり、主として社会統計学や心理統計学で用いられる用語です。
統計学で出現率を求める時、分母は誤差のない定数n(緑内障の場合は調査した標本集団の例数n)を用い、分子は誤差のある変数x(緑内障の場合は標本集団中の緑内障患者の例数x)を用います。この時、分子の変数xは二項分布をします。そのため出現率p=x/nも二項分布をします。
ベルヌーイ分布は1回のベルヌーイ試行(試行結果が0:失敗/1:成功の2種類であり、成功率pが一定という試行)について定義される離散分布であり、これをn回繰り返したものが二項分布になります。このことは、ご紹介いただいたyoutube動画を始めとして、統計学解説書でも混乱して解説されているものがけっこうあります。
二項分布は、分母の例数nが大きくなると、中心極限定理によって平均nπ、分散nπ(1-π)の正規分布で近似できます(π:母出現率、通常は標本集団の出現率pで推定します)。この近似正規分布を利用して、母出現率πの95%信頼区間を求めることができます。
youtube動画では「ベルヌーイ分布は例数が多くなると正規分布で近似できる」と解説しています。これは、ベルヌーイ試行を1回行った時はベルヌーイ分布になり、試行を何度も繰り返すと二項分布になり、その二項分布が近似的に正規分布する、ということを混乱して――はっきり言って間違って(^^;)――説明したものです。
比と割合と率の違いと出現率の信頼区間については、当館の次のページを参考にしてください。
○玄関>雑学の部屋>雑学コーナー>統計学入門
→2.4 差と比とパーセントの使い分け (注1)
http://www.snap-tck.com/room04/c01/stat/stat02/stat0204.html#note01
→3.2 1標本の計数値 (2) 名義尺度(分類データ)
http://www.snap-tck.com/room04/c01/stat/stat03/stat0302_2.html
以上、参考になれば幸いです。
- 1808. 無題 投稿者:マーシー 投稿日:2019/08/15 (Thu) 23:45:20
- 杉本様
平素はお世話になっております。
最近はずっと「統計学の基礎」を片手に、当HPの「統計学入門」、あとyoutube動画(https://yobinori.jp/video/probability-statistics.html)とにらめっこしています。(浅学で、理解が遅い点はお許しください)
本日、仕事の問い合わせで緑内障の疫学調査(http://www.ryokunaisho.jp/general/ekigaku/tajimi.html)を調べていました。
緑内障の有病率が95%CIで示されています。
私は母比率の考え方を知らなかったため、1集団500人 100集団分 ベルヌーイ分布? p=0.05(調査では有病率5.0(4.2-5.8)だったので)でランダムデータをExcelで作成しました。
それぞれの集団ごとの有病率が100データできたので、その有病率数値で母平均の推定を95%CIでしてみようと考えました。
途中で何をやっているのかわからなくなって、頭がショートして中断している状態です。
母比率の推定として計算するのと、有病率の数値の母平均の推定として計算するのでは、結果は異なるのでしょうか?
本当に難しいです。ただ魔法のような学問です。












 webmaster@snap-tck.com
webmaster@snap-tck.com